As highlighted in a previous post, adoption of cloud-based Infrastructure as a Service (IaaS) is a rapidly growing segment of the modern IT world. Whether attempting to scale out infrastructure, virtualize existing hardware, or rapidly build up a preliminary development platform one will likely find themselves looking at Microsoft's Azure.
Azure focuses on allowing users to create, scale, and migrate their environment on Microsoft managed equipment. Azure does not, however, provide much in the way of aide getting a clear, actionable picture into the state of the system being stored. In fact, users attempting to see how their Azure systems interact with their other hardware will quickly find themselves with a sizable problem; one seemingly without adequate solution.
At Pathway Systems, we understand the advantages offered by moving to IaaS products such as Azure. We are also very aware of the pitfalls users of these services face in fully understanding their environments. Luckily, we have distilled down the process of mapping out the entirety of your Azure environment to just two commands.

1. Authenticate Schematix
First, after a Schematix user who manages their team's Azure Active Directory
issues the following CML command:
:agent azure authenticate
That user will be given an HTTP link directing them to an Azure page covering the read permissions
required by Schematix, and allowing the import of Pathway Systems Schematix as a permitted
application in Active Directory.
2. Fetch Azure Information
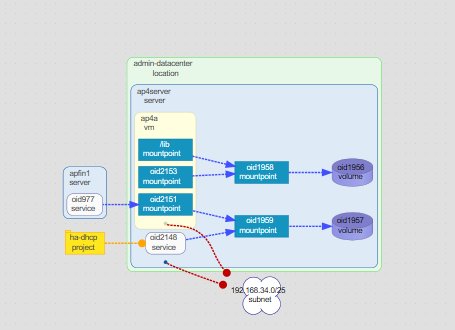
Second, after authentication, the azure agent will be used to retrieve information
about the Azure subscriptions it's been permitted read access to. This action can
subsequently be repeated by running the CML command:
:agent azure fetch
Output from this command, as with any Schematix agent, can then be written to a file,
or piped to Schematix' synchronization commands to be compared against and then
merged into the current model.
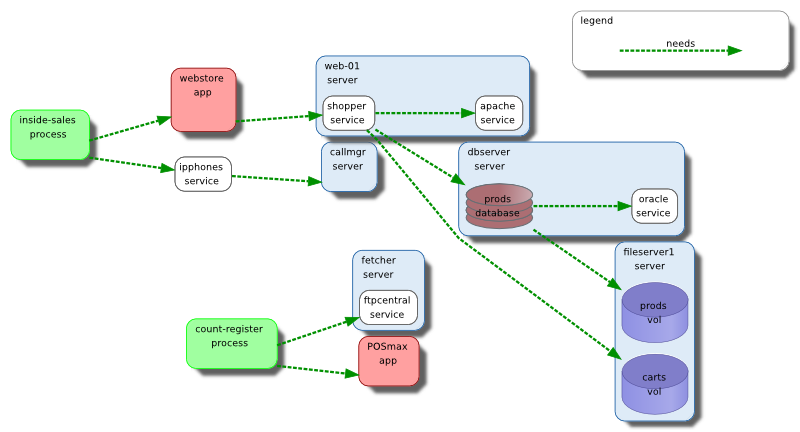
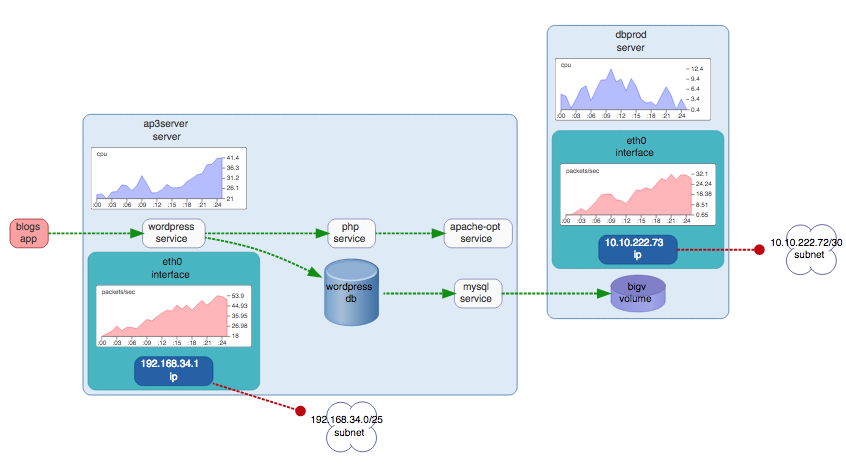
Schematix' approach to synchronization means that, after initial configuration, a single fetch command may be executed regularly, presenting the most up-to-date state for dynamic IaaS systems, such as Azure. Furthermore, after merging the auto-discovered information with the user-curated information within the model, users of Schematix will finally have the tools necessary to gain actual insight into how their Azure equipment interacts with their other systems, and be able to leverage the full range of Schematix features across their entire environment.

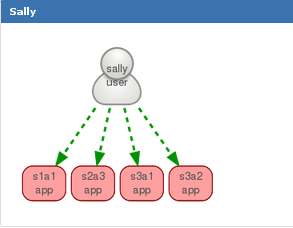



 Application Dependency Mapping Schematix
Application Dependency Mapping Schematix